
Big Data ist ein seit einigen Jahren oft gebrauchter Begriff, der die Herausforderungen und Potentiale durch stark anwachsendende Datenvolumen in fast allen Lebensbereichen umreißt. Große Mengen von Daten unterschiedlichster Natur – z.B. Texte aus sozialen Netzwerken oder Sensormesswerte – die sich schnell ändern oder mit hoher Geschwindigkeit erzeugt werden, stehen oft im Vordergrund.
Ist Big Data für mein Unternehmen relevant?
Um diese Frage zu beurteilen, ist es hilfreich, sich dem Thema pragmatisch zu nähern. Ob es sich in konkreten Anwendungsfällen beispielsweise um sehr große Datenmengen handelt oder nicht, ist oft nicht ausschlaggebend. Wesentlich für Unternehmen ist vielmehr:
- Welche derzeit gering oder nicht genutzten Daten besitzen hohes Nutzenpotential?
- Lassen sich diese Potentiale mit bestehenden oder neuen Technologien effizient erschließen?
Bei der ersten Frage sollten interne Daten des Unternehmens sowie externe Daten aus dessen Marktumfeld betrachtet werden. Ihr möglicher Nutzen kann sich auf bestehende Geschäftsprozesse oder gänzlich neue Produkte, Services und Geschäftsmodelle beziehen. Inwieweit moderne Big Data-Technologien, wie Hadoop oder In Memory-Datenbanken, zur Datenerfassung und -auswertung eingesetzt werden können, klärt die zweite Frage.
Obwohl die Datenmengen mittelständischer Betriebe meist um vieles kleiner sind, als die von Großunternehmen, können sich auch für sie gänzlich neue Möglichkeiten erschließen. Ein Anwendungsfall, der sowohl für große, als auch für kleinere Handelsunternehmen interessant sein kann, ist die Echtzeit-Optimierung von kunden- und situationsspezifischen Angeboten in einem Webshop während eines Kundenbesuchs. Verwendet werden hierzu typischerweise selbstlernende Prognosealgorithmen, die mit unternehmenseigenen Kundendaten sowie externen Informationen über Kundensegmente, Marken, Bedürfnisse und Trends gefüttert werden. Hürden beim Einsatz neuer komplexerer Technologie zur Datenerfassung und Verarbeitung, die für Mittelständler mit eigenen Ressourcen oft nicht zu bewältigen sind, können durch die Verwendung von Cloud-Lösungen einfacher überwunden werden.
Wie werden vielversprechende Anwendungsfälle entdeckt?
Die Identifikation geeigneter Big Data-Anwendungsfälle ist für viele Unternehmen eine große Herausforderung. Eine gemeinsame Untersuchung der Hochschule und Universität Mainz zeigt, dass die diesbezüglichen Vorgehensweisen und Organisationsformen sehr unterschiedlich sind. Die Bandbreite reicht von unabhängigen Initiativen einzelner Fachbereiche, bis hin zu zentral koordinierten Projekten sogenannter Big Data Center of Excellence. Startpunkt sollte immer die Festlegung von Zielen sein. Geht es beispielsweise vornehmlich um die Verbesserung bestehender Geschäftsprozesse in einem bestimmten Fachbereich oder um innovative Ideen für neue Produkte und Dienstleistungen? Die Methoden zur Ideenfindung sowie die hieran zu beteiligenden Mitarbeiter sind dann gemäß diesen Zielen festzulegen.
Stehen beispielsweise gänzlich neue Geschäftsmöglichkeiten im Vordergrund, so sind insbesondere Mitarbeiter, die sich von bestehenden Prozessen des Unternehmens frei machen können, wertvoll. Auch ist es oft wenig hilfreich, sofort über mögliche technische Hürden zu sprechen. Andererseits sind Kenntnisse über aktuelle Trends im Branchenumfeld, verwendbare interne und externe Daten sowie neue Analyseverfahren umso wichtiger.
Eine effektive Bewertung von Ideen zur Vorbereitung von Investitionsentscheidungen ist ein weiterer wesentlicher Schritt. Hierbei ist ein gesamtheitlicher Blick notwendig, der fachliche, technische, organisatorische und regulatorische Aspekte berücksichtigt.
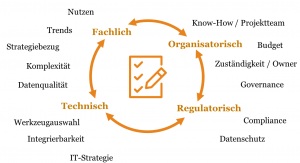
Typische Fragen aus unterschiedlichen Projekten sind: Reicht die Datenqualität aus, um mit neuen analytischen Verfahren Gründe für die Veränderung von Marktanteilen in der Konsumgüterbranche zu identifizieren? Wird ein mögliches Scoring von Konsumentendaten aus sozialen Netzwerken für die Risikoabschätzung von Kreditausfällen von Marktteilnehmern akzeptiert? Wie groß ist der Integrationsaufwand für Sensordaten mit einem bestehenden Enterprise Asset Management-System, um Wartungsvorhersagen für Produktionsanlagen zu ermöglichen?
Methodenbaukasten
Ziel eines aktuellen Projekts der Hochschule und Universität Mainz ist es, Methoden zur erfolgreichen Identifikation und Bewertung von Big Data-Anwendungspotentialen bereitzustellen. Eine gemeinsame Betrachtung wesentlicher Aspekte über Business, Daten und Technologie ist hierfür grundlegend. Wichtige Komponenten sind:

Erste Ergebnisse zeigen, dass es nicht „die“ erfolgreiche Methode gibt. Unterschiedliche Rahmenbedingungen und Ziele erfordern unterschiedliche Vorgehensweisen. Wichtige Einflussfaktoren sind beispielsweise Branche, Größe und das bestehende Geschäftsmodell sowie die gegenwärtige Unternehmensstrategie. Wesentlich sind auch der Reifegrad der gegenwärtigen Datenverarbeitung und die zugehörigen technologischen Voraussetzungen. Liegt der Schwerpunkt der Geschäftsstrategie beispielsweise auf neuen Dienstleistungen, sind Methoden wie Design Thinking, die dem Prinzip „Fail Fast“ folgen, oft zielführend. Hier werden neue Ideen durch schnell und kostengünstig erstellte Prototypen unmittelbar ausprobiert. Bei einer positiven Bewertung werden sie weiterverfolgt, bei festgestellter Nicht-Eignung sofort, ohne Hemmung, verworfen.
Derzeit werden in dem beschriebenen Forschungsprojekt aktuelle Vorgehensweisen im Bereich Big Data in unterschiedlichen Unternehmen und Branchen untersucht. Die zugehörigen Ergebnisse dienen als Ausganspunkt zur Konstruktion passender Methodenbausteine. Diese werden dann in Unternehmen erprobt und optimiert. Unternehmen, die an einer Projektteilnahme interessiert sind und ihre Erfahrungen gegebenenfalls mit den Forschungspartnern und anderen Firmen austauschen möchten, sind herzlich willkommen.
Zu den Autoren:
Prof. Dr. Gunther Piller ist Professor für Wirtschaftsinformatik an der Hochschule Mainz
Univ. Prof. Dr. Franz Rothlauf leitet den Lehrstuhl für Wirtschaftsinformatik und BWL an der Johannes Gutenberg Universität Mainz